2025-01-29
ADLC — Building AI That Works: The Agent Development Lifecycle Guide
ADLC — Building AI That Works explains the Agent Development Lifecycle, its six phases, and why data annotation is the foundation of reliable agentic AI.
ADLC — Building AI That Works
ADLC (Agent Development Lifecycle) is the engineering discipline for building, deploying, and governing autonomous AI agents in production. Unlike traditional SDLC, ADLC treats data, prompts, evaluations, and runtime behaviour as first-class artefacts. ADLC — Building AI That Works means anchoring every phase in high-quality labeled data, continuous evaluation, and governed feedback loops.
Enterprise AI teams are discovering that the methods that shipped reliable web apps do not ship reliable agents. Agents reason, act, and call tools. They drift. They hallucinate. They need a lifecycle built for non-deterministic systems — and that lifecycle is the Agent Development Lifecycle.
This guide explains the six phases of ADLC, why agentic AI development demands new engineering muscles, and how data annotation for agentic AI sits at the heart of every working agent in production.
What Is ADLC and How Does It Differ from SDLC?
ADLC (Agent Development Lifecycle) is a structured framework for designing, building, testing, deploying, and continuously improving AI agents — software entities that perceive context, reason over goals, and take autonomous actions using tools, APIs, or other agents.
SDLC (Software Development Lifecycle) assumes deterministic behaviour: given the same input, the system returns the same output. Test once, ship forever. Agents break that assumption.
Here is the core shift:
- SDLC validates code paths. ADLC validates reasoning behaviour across thousands of probabilistic trajectories.
- SDLC treats data as input. ADLC treats labeled training, evaluation, and feedback data as the primary engineering asset.
- SDLC ships features. ADLC ships capabilities that must be monitored, re-evaluated, and re-aligned as models and tools evolve.
- SDLC uses unit tests. ADLC uses eval suites — graded annotated test cases that score agent decisions across correctness, safety, and reasoning quality.
- SDLC debugging is a stack trace. ADLC debugging is a trace across prompts, tool calls, and intermediate reasoning steps that requires human-annotated ground truth to diagnose.
The practical implication: an enterprise cannot move from SDLC to ADLC simply by adopting an LLM (Large Language Model) library. It must build an annotation, evaluation, and feedback infrastructure that runs continuously — the layer where most agent projects quietly fail.
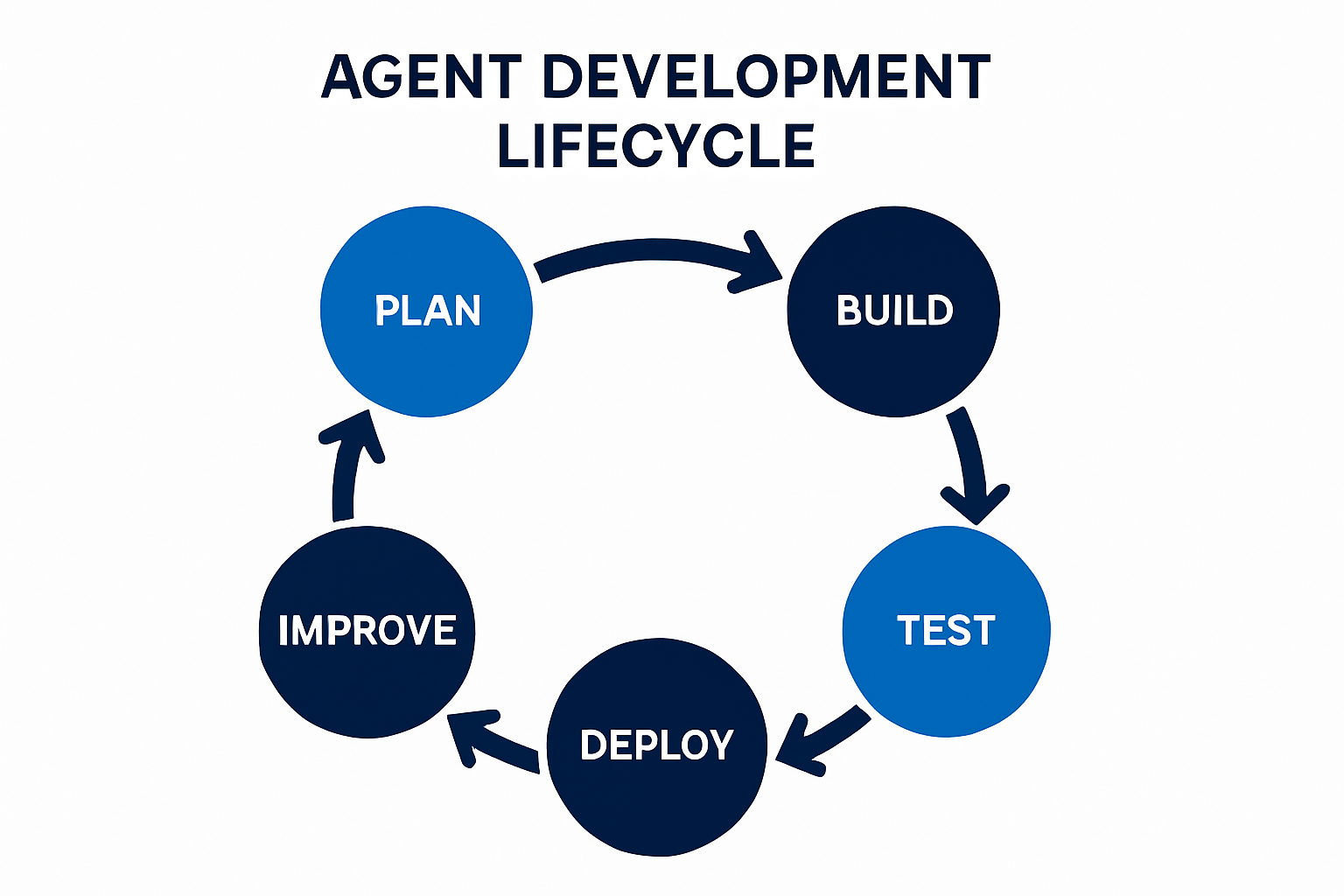
What Are the 6 Phases of the Agent Development Lifecycle?
The Agent Development Lifecycle consists of six interlocking phases. Each phase produces artefacts that feed the next, and each depends on high-quality annotated data to function.
1. Plan — Define the Agent's Goals, Boundaries, and Success Metrics
Specify what the agent must do, what it must not do, the tools and data it can access, and how success will be measured. Outputs include a capability spec, a risk register, and an initial evaluation taxonomy — the schema annotators will later use to label good and bad agent behaviour.
2. Build — Compose the Agent
Design prompts, retrieval pipelines, tool integrations, and orchestration logic. Fine-tune base models where needed using domain-aligned instruction-response datasets and RLHF (Reinforcement Learning from Human Feedback) annotations. This is where ASPL's AI data annotation services provide the labeled corpora that turn a generic model into a capable, domain-specific agent.
3. Test — Evaluate Behaviour Across Trajectories
Run the agent through annotated eval suites that cover happy paths, edge cases, adversarial prompts, and tool-failure scenarios. Each test case is human-graded against the taxonomy defined in Phase 1. Without ground-truth annotations, "passing" means nothing — you only know your agent did something, not whether it did the right thing.
4. Deploy — Ship with Guardrails
Release the agent behind policy filters, rate limits, tool-permission scopes, and human-in-the-loop checkpoints for high-risk actions. Capture every trace, prompt, response, and tool call to a governed log for downstream review.
5. Monitor — Observe in Production
Track latency, cost, tool-success rates, refusal rates, and drift indicators. Sample live traces and route them to annotators for graded review. Production monitoring without annotation is just telemetry; with annotation, it becomes a continuous quality signal.
6. Improve — Close the Feedback Loop
Feed annotated production traces back into eval suites, fine-tuning datasets, prompt revisions, and tool fixes. This is the active learning flywheel — and it is what separates agents that work today from agents that keep working tomorrow.
The phases are cyclical, not linear. Mature ADLC teams iterate through Plan → Improve continuously, with annotation pipelines running in parallel to every phase.
Why Is High-Quality Labeled Data Critical for Agentic AI?
Agents are only as reliable as the data that trained them, the evaluations that graded them, and the feedback that corrects them. Data annotation for agentic AI is not a one-off preprocessing step — it is the operational backbone of ADLC.
Three reasons high-quality labeled data is non-negotiable:
-
Training signal quality determines ceiling performance. Noisy or inconsistent labels in fine-tuning datasets cap the agent's accuracy long before architecture or model size do. Studies across enterprise GenAI deployments repeatedly show that label quality outperforms model size for domain-specific tasks.
-
Evaluations are the only objective truth. Without annotated eval sets scored by domain experts, every release decision is a guess. Eval suites are how teams know whether a new prompt, model version, or tool integration actually improved the agent — or silently degraded it.
-
Production safety depends on annotated feedback. Real-world traces — the messy, ambiguous, edge-case behaviour agents exhibit at scale — must be reviewed and labeled to feed the improvement loop. Active labeling, where annotators continuously grade sampled production data, is the runtime quality mechanism that keeps drift in check.
Poor labels do not just slow training. They make agents uncontrollable: a governance failure dressed as a data quality problem.
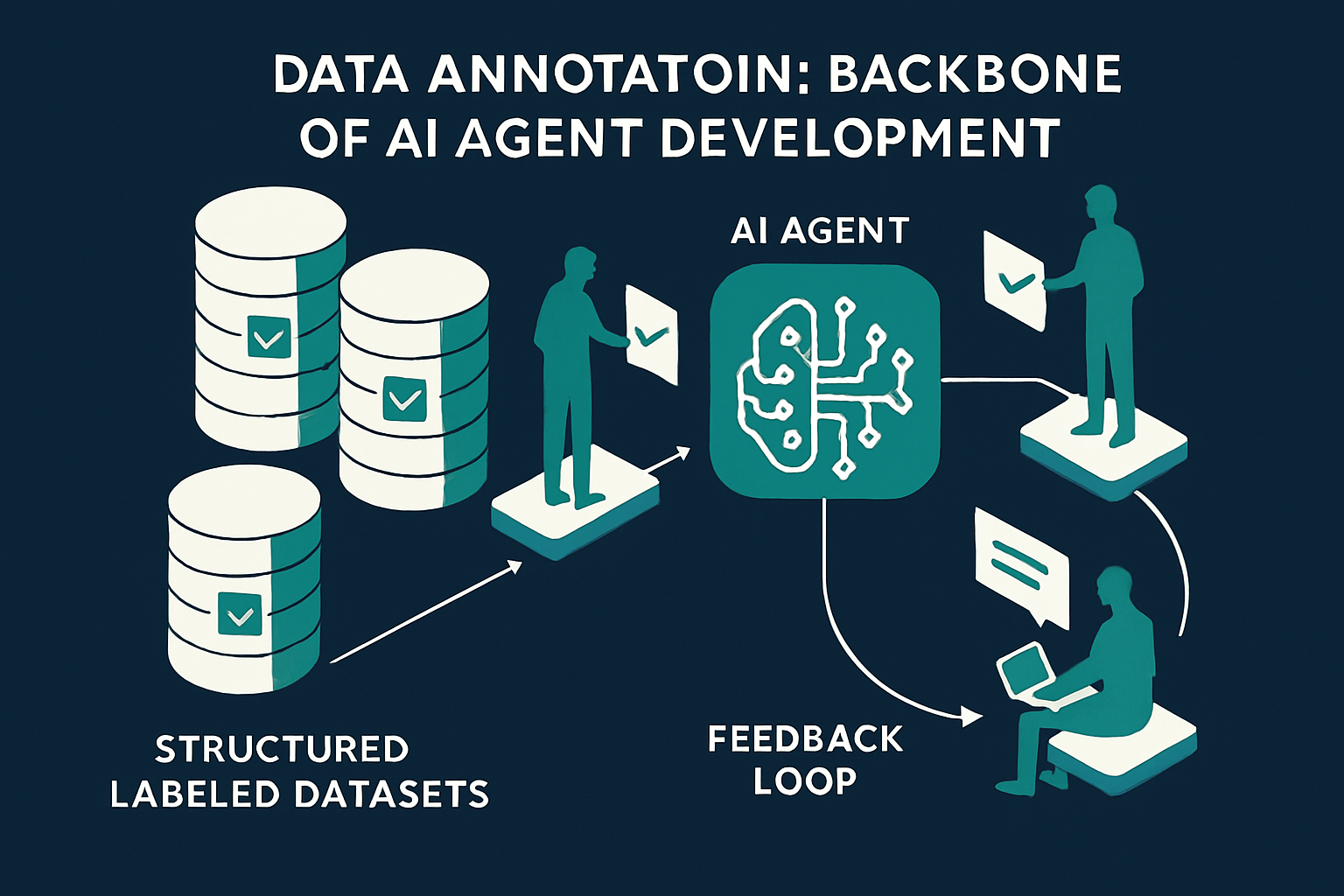
How ASPL's Annotation Stack Supports Each ADLC Phase
ASPL's annotation platform, PIXEAL, is designed for the lifecycle realities of agentic AI — not just static dataset delivery. Here is how PIXEAL-powered annotation maps to each ADLC phase:
- Plan — Co-design the annotation taxonomy and evaluation rubrics with your AI team. Define what "good" looks like before a single label is created.
- Build — Deliver domain-aligned instruction-response datasets, RLHF preference data, and bias-filtered corpora for fine-tuning and alignment.
- Test — Build graded eval suites with human-expert scoring across correctness, safety, reasoning quality, and tool-use appropriateness.
- Deploy — Provide labeled guardrail datasets for policy filters, content moderation, and refusal-classification models.
- Monitor — Run continuous annotation pipelines on sampled production traces with multi-stage QA and inter-annotator agreement tracking.
- Improve — Feed annotated traces back into fine-tuning and eval expansion through governed, auditable workflows in secure ODC (Offshore Development Centre) environments.
Explore our Pixeal annotation platform to see how the full annotation lifecycle is governed under one system, and how SourceOptima accelerates the engineering side of agent development.
Common ADLC Failure Modes — And How to Avoid Them
Most agent projects do not fail because the model is wrong. They fail because the lifecycle around the model is missing. The patterns repeat across industries:
- No eval suite before launch. Teams ship agents based on demo behaviour, then discover failure modes from customers. Fix: build an annotated eval suite in Phase 1 and gate every release on it.
- Evals built by engineers, not domain experts. Generic test cases miss the nuanced failures that matter in healthcare, legal, automotive, or financial domains. Fix: use domain-specialist annotators who understand the context.
- No production trace annotation. Telemetry tells you the agent ran. Annotation tells you whether it ran correctly. Fix: sample and label 1–5% of production traces continuously.
- Feedback loop never closes. Annotated failures pile up but never feed back into training or prompts. Fix: schedule monthly improvement sprints where annotated traces become new eval cases and fine-tuning examples.
- Treating annotation as a vendor task. Annotation cannot be outsourced and forgotten. It must be a governed, integrated capability inside ADLC. Fix: partner with annotation providers who deliver end-to-end lifecycle support, not point-in-time labels.
ADLC Phases: Testing, Monitoring, and the Cost of Skipping Either
Search interest in ADLC phases testing monitoring reflects a real enterprise pain point: teams understand they need to test and monitor, but underestimate the annotation cost and organisational design required to do either well.
A practical rule of thumb for enterprise ADLC budgets:
- Build (model, prompts, tools): 30% of effort.
- Annotate (training, eval, and feedback data): 40% of effort.
- Monitor and improve (tracing, sampling, re-labeling): 30% of effort.
Teams that under-invest in annotation routinely spend 2–3x more in remediation, customer trust recovery, and re-training cycles after agent failures in production. Quality-first annotation is the lowest-cost path to reliable agentic AI — even when it looks expensive on the upfront invoice.
Building AI That Works: Start with the Lifecycle, Not the Model
The teams shipping reliable agents are not the ones with the biggest models. They are the ones with the most disciplined Agent Development Lifecycle — and the most rigorous annotation infrastructure feeding it.
ADLC — Building AI That Works is not a slogan. It is a commitment to treating agents the way safety-critical systems have always been built: with explicit specifications, graded evaluations, continuous monitoring, and a closed feedback loop where humans, data, and models improve together.
If your team is moving from prototype to production agents, the right place to start is your data layer. Talk to ASPL about scoping the annotation, evaluation, and feedback infrastructure your Agent Development Lifecycle needs. Visit our annotation services page or contact our team to design an ADLC-ready data strategy built for agents that actually work.